Real-time Analysis of Network Flow Data with Apache Spark on Databricks
Network monitoring at scale is a big data problem that requires a big data platform¹. This post describes how to perform real-time analysis while storing network flows metadata in a data lake on AWS S3 using Spark on Databricks.
Background
Network visibility and analysis relies on data from the network. These days it is not uncommon for enterprise networks to carry very large amount of data in the network traffic. While packet capture has been the tool of choice for a long time, it is obvious that it is too costly to use as the preferred way of performing data analysis. The metadata is carrying the information actually needed for analysis, while the full content of a packet payload may become relevant in forensic analysis, for instance to find out the extent of a breach.
Network flows composed of only a few attributes are a thing of the past. Modern network flow collectors, such as the highly performing and inexpensive nProbe from Italian company NTOP², can inspect packets as an inline tool and extract Layer-4 to Layer-7 metadata as network flows, that is where it counts, and at speed of up to 100 Gbit using commodity hardware.
This posts describe an architecture and the software used to perform real-time analysis of network flows from a number of nProbe collectors, while storing data on a data lake in S3 in such a way to allow for fast retrieval.
System Architecture
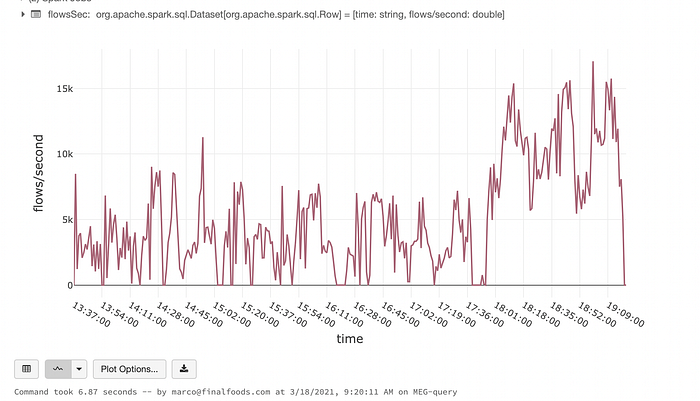
The system used for data ingestion and analysis is composed of one or more nProbe flow collectors, a Kafka message broker in AWS, and a Spark cluster composed of one driver and four workers in Databricks, all r5.large EC2 instances with 122GB of RAM. While this is a fairly small cluster, it was able to handle a sustained traffic of 15k flows/sec and to query more than 100 million flows in the data lake in less than 15 seconds.

Network Flows Format
The nProbe collector allows to specify the format of NetFlow v9/IPFIX flows, and to export them to a Kafka broker in JSON. The individual data options currently supported by nProbe total almost 200 , which include the attributes specified in the NetFlow v9 RFC³.
For this setup, in addition to selecting JSON as format and exporting the flows to the Kafka server, 50 fields are indicated in the nprobe.conf configuration file, including a custom field with a constant to identify the collector:
Ingestion Pipeline
All the processing is performed in the ingestion pipeline, which is broken into the steps illustrated in the diagram below:

Reading from Kafka
As initial setup, two dedicated topics in the Kafka server need to be created:
$ ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic netflows$ ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic netflows-events
The first is used by the collectors to publish the NetFlows. The second topic is used in the pipeline to publish real-time suspicious detections for downstream processing.
In the Databricks notebook, it is convenient to mount an existing, empty, S3 bucket to the Databricks File System (DBFS) allowing access to objects in object storage as if they were on the local file system:
Note: for proper S3 authentication, both the AWS key and secret need to be set as Spark environmental variables in the Databricks cluster, or added to the bucket’s path. Also, the newer s3a version of the s3n native connector, that uses Amazon’s libraries, is the preferred Spark S3 connector.
Kafka is a native data source in Spark and therefore it is fairly straightforward to read a stream from a Kafka topic into a Spark dataframe:
The schema of the jsonDF is of two attributes: an arrival timestamp added by Kafka and the value, which is a string containing the JSON NetFlow.
Data Enrichment
Spark has a SQL function called from_json() that takes an input column of JSON data and produces a structured output column. However, to call that function, a schema for the JSON objects needs to be provided. The following is the hard-coded schema for the raw NetFlows as a Scala structure:
With the defined schema, it is then possible to parse the JSON held in the value column using the from_json() function to subsequently access the data using column names like json.IN_PKTS and json.IPV4_SRC_ADDR. There is an opportunity to flatten the schema as well as illustrated in the code below.
Note:
- Use a projection to keep only 46 attributes to keep for storing and analysis
- In the process, assign columns simpler names
Also note:
- The
L7_PROTOcolumn contains a decimal number of the form XXX.YYY indicating the master protocol XXX and application protocol YYY. This is split into two distinct columns using the integer and decimal parts. - Addition of the
Durationcolumn as obtained by subtractingFLOW_START_MILLISECONDSfromFLOW_END_MILLISECONDS. - The
FLOW_START_MILLISECONDSandFLOW_ENDcolumns contain Epoch time, which are converted to aTimestamp. - Removal of the Kafka arrival timestamp, as
FLOW_START_MILLISECONDSandFLOW_END_MILLISECONDStimestamps are more accurate.
Save NetFlows to S3
The following code saves NetFlows as S3 parquet compressed objects as they stream in from Kafka, one for every minute. The objects are organized hierarchically by year, month, day, and hour in a “data lake” fashion:
Note:
- Using
partitionBy()as above results in a Hive-style partitioning, which is needed to speed up queries
A short list of S3 objects resulting from the workflow:

NetFlows Ingestion Rate
The following code uses a 1 minute window and a 5 minutes watermark, to aggregate the NetFlows and to show the number of message being processed and ingested per second:
The chart below was obtained by running the code above (without the watermark) as a query on four hours of NetFlows held on S3. It shows how the cluster used for the ingestion can sustain 15k of flows per second:
Real-time Analysis
As an example of how real-time analysis is performed on the NetFlows from the ingestion pipeline, the code below shows the detection of flows using an old, and possibly suspicious, TLS protocol version. The detected NetFlows are then published to a dedicated Kafka topic to be consumed by an event manager downstream:
Save Rollups to S3
To save on query time, or having to run a cluster for standard queries, aggregating NetFlows statistics as they are ingested, storing the results into a S3 object, is an efficient way to produce the equivalent of rollups.
The following is an example of creating 1 minute host statistics and saving them to S3 in a JSON file:
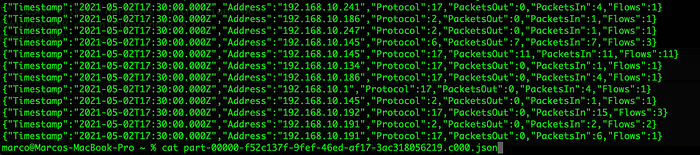
The following is an example of some statistics in the JSON files produced:
Summary
Apache Spark has a steep learning curve, but it is a very powerful tool that allows writing pipelines that combine data ingestion, real-time analysis and data aggregation. This proves to be very useful for NetFlows, and to provide visibility of network traffic particularly when used with modern flow collectors that generate metadata as result of deep-packets inspection, such as the nProbe collector from NTOP².
The examples above are representative of how to provide real-time detection, network traffic analysis, and data aggregates using a big data approach with streaming data. Given the plethora of attributes in the NetFlow format provided by modern collectors it is easy to imagine the power of this approach in giving network visibility to the security teams, and in perspective as a foundation for an AIops system as well.
Databricks is a mature platform that removes the difficulties associated with integrating libraries and deploying a Spark application in a cluster. It also provides a convenient JDBC connector out of the box. Databricks also have a relatively expensive but very good intensive online training program.
In a second follow-on article, a real-time dashboard for Network Flows data will be presented.
[1] A. D’Alconzo, I. Drago, A. Morichetta, M. Mellia and P. Casas, “A survey on big data for network traffic monitoring and analysis”, IEEE Trans. Netw. Service Manag., vol. 16, no. 3, pp. 800–813, Sep. 2019.
